
dispatch_once
之前这篇文章dispatch_semaphore搬运源码搬了dispatch_semaphore相关的方法,最近看了dispatch_once,来扒一扒。
看个问题
|
|
想想这个代码会输出什么东西呢?那我们先看看 dispatch_once 是怎么实现的吧。
dispatch_once 实现
|
|
我们可以忽略那个for循环,可以看到有三种情况:
case 1: 第一次进入
if (os_atomic_cmpxchg(vval, NULL, tail, acquire)
第一次进入会直接执行传入的block,然后设置已执行过的标记,最后去唤醒 其它地方同时第一次进入的排队。
case 2: 第一次完成之后进入
if (vval == DISPATCH_ONCE_DONE) break;
第一次完成之后进入时,会发现标记已经是 DISPATCH_ONCE_DONE,然后什么也没做。
case 3: 多处同时第一次进入
这时会在 _dispatch_once_waiter_s dow 的尾部多加一个排队等待,主要是这里 _dispatch_thread_event_wait(&dow.dow_event)。
问题的输出
最后看看最开始那个问题的输出吧:
然后线程就卡住了,这可能还不够清楚到底发生了什么,那我们这时暂停程序看看调用栈是什么样吧:
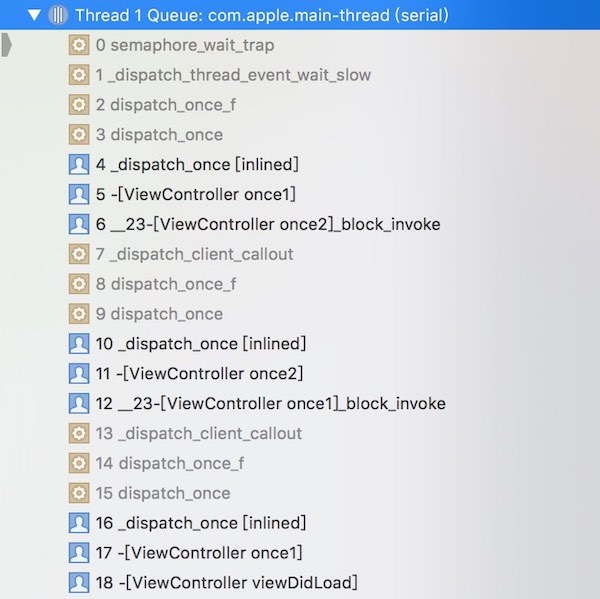
可以发现执行卡在了 _dispatch_thread_event_wait_slow。
代码第一次进入 once1 是 case 1;然后进入了 once2 是 case 1;这时又递归进入了 once1 是 case 3 了。
这些都在同一线程,所以就卡住了,因为 case 3 卡住了当前线程在等待第一次进入 once1 的执行结束,而当前线程已经被卡住了,所以第一次进入的 once1 没有办法继续执行。
这里还有一个不明白的地方,没看明白 os_atomic_cmpxchg 是怎么实现的?
