
扒了扒libdispatch源码
前几天扒了一下libdispatch的源码,当前最新的是 libdispatch-703.30.5,之前也在网上查了一些博客,发现源码有点对不上,应该是代码比较老了吧。之前对GCD的认识都比较浅:
- 一直有个误区认为 dispatch_sync 是卡住当前线程,然后去异步线程执行,原来并不是如此;
- 一直认为 dispatch_sync 死锁的是线程,原来并不是如此;
- 一直不是很清楚 libdispatch 中 队列 和 线程 是如何协作的
- 一直想知道 dispatch_barrier 是怎么实现的
- 一直想知道为什么 dispatch_sync 死锁崩溃是输出的信息是 barrier
- ……
好了,来来来,扒扒源码就全知道了,当然源码中我还是有很多疑惑的地方,欢迎大家拍,反正我只是搬运工,哈哈😄
全景结构图
先看这张泛滥了的图吧:
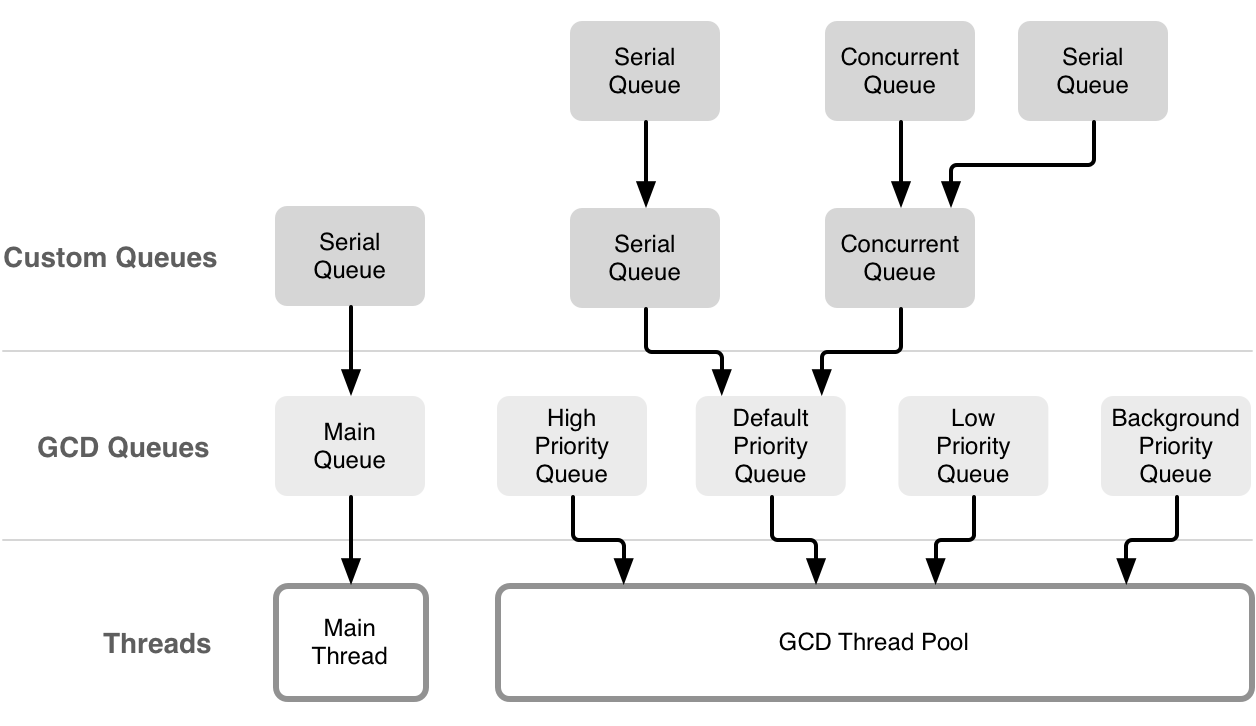
从上图我们可以得到的信息是:
- 只有 Main-Queue 的任务可以提交到 Main-Thread 上
- 系统提供的所有的 Default-Queues 会共享一个 Thread-Pool
- 我们自己创建的所有 Custom-Queues 都会和 Default-Queues 有某种联系
- 关于线程的任务调度用户不能也不需要参与
关键数据结构
先记下几个关键的数据结构吧,等会儿好返回来查,有个东西提前说明一下:
这些结构体都会有两个,一个是 \**_t* 另一个是 \**_s* ,其中 \**_t* 是 \**_s* 的指针类型,_s是结构体。比如 dispatch_queue_t 和 dispatch_queue_s。
dispatch_object_s 这个结构体可以代表所有的 gcd对象,我说OC中的 id 类型,你一定就知道是什么了。
dispatch_continuation_s
|
|
dispatch_continuation_s 是中的任务的结构体,被传入的 block 会被变成这个结构体对象塞入队列
dispatch_queue_s
|
|
dispatch_queue_s是队列的结构体,在它的 do_vtable 中有很多函数指针,对应队列的一些操作方法,对应有一些宏可以调用队列中的这些方法。比如, do_dispose 方法对应有一个宏 dx_dispose :
|
关键就这两个数据结构 dispatch_continuation_s 和 dispatch_queue_s。
dispatch系列常用的方法
接下来我们看看dispatch系列几个常用的方法吧。
dispatch_queue_create
|
|
- 每一个用户创建的队列都会指向一个 root queue,这里的指向是说 do_targetq 指针,就是开始那张图中的的箭头走向;
- 串型队列和并行队列是通过 width 区分的,串型为1,并行为32766;
- 通过上面的代码可以发现,队列的 dq_serialnum 是从16开始自增的,其中1-15号队列被系统占用;
- do_targetq 的意义暂时还不是很明白,等大侠解答。
dispatch_sync
|
|
- 我们可以看到 dispatch_sync 有两种情况:
- 串型队列,那么处理方式会和barrier一样;
- 并行队列,会去更新队尾,然后原地等待该任务到达执行,任务到达后原地执行,所以在里是在当前线程执行的;
- 在执行任务的前后,分别会对当前线程的现场进行保存和恢复;
- 等待任务到达在 _dispatch_thread_event_wait 中,使用了 semaphore + while循环 的方式;
- 串型队列的 dispatch_sync 和 dispatch_barrier_sync 一样,那我们下面来看。
dispatch_barrier_sync
|
|
- 可以发现在 dispatch_barrier_sync 开始的地方有一段注释说明,大意是说:由于局部线程切换的副作用,所以首选在当前线程执行sync任务。但是,sync提交到主队列的任务必须在主线程执行。这一点不难理解,因为一开始的图能得知,主队列和其他队列所对应的线程池是独立的。这也比较make sence,因为对于UI的操作需要放在同一线程(主线程),否则可能很难避免界面错乱。因此,在
if (_dispatch_queue_is_thread_bound(dq)) 的判断中决定是否需要切换线程。 - 在检测是否有死锁的地方,我们可以发现打出的崩溃信息是 dispatch_barrier_sync called on queue already owned by current thread,这解答了为什么在当前线程 dispatch_sync 到当前队列时输出的是 dispatch_barrier_sync 了;
- 剩下的操作就和 dispatch_sync 一样了。
dispatch_async
|
|
- 相对来说 async 的系列操作就比 sync 的系列操作简单一下,因为它不需要再关心执行的时机;
- 如果是并行队列,开始时会循环查找队列的 target_queue,对于 target_queue 我始终不是特别明白意义 (求大神斧正) 。我猜应该和任务的并发执行有关,因为并发队列是可以并行执行任务的,所以如果当前队列被一个大任务卡住了,那么它可以为下一个可并发执行的任务找一个合适的 target_queue 扔进去,这就并发了。(求大神斧正)
- 最后找到合适的queue后呢,就把任务push到队尾就好;
- 如果更新队尾时发现队尾为空,说明当前队列处于闲置状态,那么还要更新一下队首,然后唤醒。
dispatch_barrier_async
|
|
- 咦?我们发现 dispatch_barrier_async 怎么这么简单粗暴?是的,把任务塞到队尾就不管了,比 dispatch_async 还省事。但是有一点不同需要注意,我们可以看到在 dispatch_barrier_async 中,赋给任务的 dc_flags 标记是:
dc->dc_flags = DISPATCH_OBJ_CONSUME_BIT | DISPATCH_OBJ_BARRIER_BIT | DISPATCH_OBJ_BLOCK_BIT;
可以发现相对 dispatch_async 多了 DISPATCH_OBJ_BARRIER_BIT 这位。是的,这一位标记决定了执行时的方式; - 那问题就来了,唤醒队列(do_wakeup) 和 执行队列任务(do_invoke) 到底是怎样的呢?我们下面来扒一扒。
do_weakup
|
|
- wakeup比较简单,上面的方法是 “queue”, “serial-queue”, “concurrent-queue” 的 do_wakeup 函数指针的处理方式;
- 进入之后首先判断队列中是否有排队的任务,如果有就各种合法性判断之后添加一个入队列的状态标记位;如果被唤醒的队列没有任务排队,那就离开了。
- 最后检查一下新老状态中是否有“入队列”的状态变化,有的话就调用 _dispatch_queue_class_wakeup_enqueue 方法;
- _dispatch_queue_class_wakeup_enqueue 方法里最终会在 com.apple.libdispatch-manager 队列中被调度。这里不甚明白,请大神斧正。
do_invoke
|
|
- do_invoke 就相对比较复杂了,这里面也出现了很多风骚的 goto 语句,估计是为了提高执行效率吧;
- _dispatch_queue_class_invoke 中做了很多状态判断和转移,真正执行任务的地方是调用 _dispatch_queue_drain,同时会返回一个queue,然后继续在 _dispatch_queue_class_invoke 中判断这个queue是否需要后续操作;
- _dispatch_queue_drain 方法通过参数区分串型处理或并行处理,开始时先判断队列当前是否是在barrier任务的处理中,再通过一个 while 循环来弹出任务执行,核心操作就在 while 循环中;
- 在 while 循环中取出一个任务后:
- 如果是串型处理,那么会在while循环中依次将队首任务弹出队列并执行;
- 如果是并行处理,同样会依次将任务出队列,进行转发到其它线程执行;
- 如果是一个barrier任务,同时不在 DISPATCH_QUEUE_IN_BARRIER 状态中,那么会推出执行,将任务返回给 _dispatch_queue_class_invoke,最后会调用 _dispatch_queue_drain_deferred_invoke 方法将这个任务推迟。
- 如果是一个barrier任务,同时在 DISPATCH_QUEUE_IN_BARRIER 状态中,那么这个就是要等待的barrier任务,将会直接执行。
- 这里写的不是很清晰明了,因为这里面的各种状态和标记位有点绕晕了,等大神指点。
最后
就酱,大概知道了dispatch的冰山一角,libdispatch里还有很多很多东西,比如 semaphore, timer, group,这次先挖这么多。
另外,发现在全局的queue里面有一个叫 “runloop-queue” 的队列,这个应该就是往runloop中提交任务的队列,更具 runloop 的源码,循环中会询问dispatch是否有任务插入执行,应该就是检查这个队列。
这篇文章和后面的引用都不错:
从NSTimer的失效性谈起(二):关于GCD Timer和libdispatch
感谢作者
